Week 28: Multimodal file attachment support & Text-to-Speech expansion
Sep 7th, 2025
File attachment support
120 AI Chat now handles PDF attachments directly in conversations. Users can upload PDFs to discuss content, get summaries, or ask questions about specific parts.
PDF preview and processing: The app uses macOS's PDF tools for inline previews, showing pages without opening external viewers. This keeps the workflow within the chat.
AI content analysis: Models can read the PDF text, identify key sections, and respond to queries like summarizing findings or explaining terms. For example, upload a research paper and ask for an overview of the results.
Visual input capabilities with image chat
Image uploads are now supported, letting users attach photos, screenshots, or diagrams for AI review and discussion.
Integration with Gemini models: Works with Google Gemini, including the Nano Banana model from last week, to analyze uploaded images. The AI can describe elements, suggest changes, or create related images in the same thread.
Use in workflows: Attach an image of a design and ask for feedback or variations. The app keeps the image visible for reference in follow-up messages.
Multi-file support
Up to three files can be attached at once, supporting analysis across multiple documents or images.
Cross-file tasks: Compare two PDFs for differences or review an image alongside a document. The AI maintains context from all attachments.
File persistence: Attached files stay available in the conversation, so users can refer back without re-uploading.
Swiss AI model integration
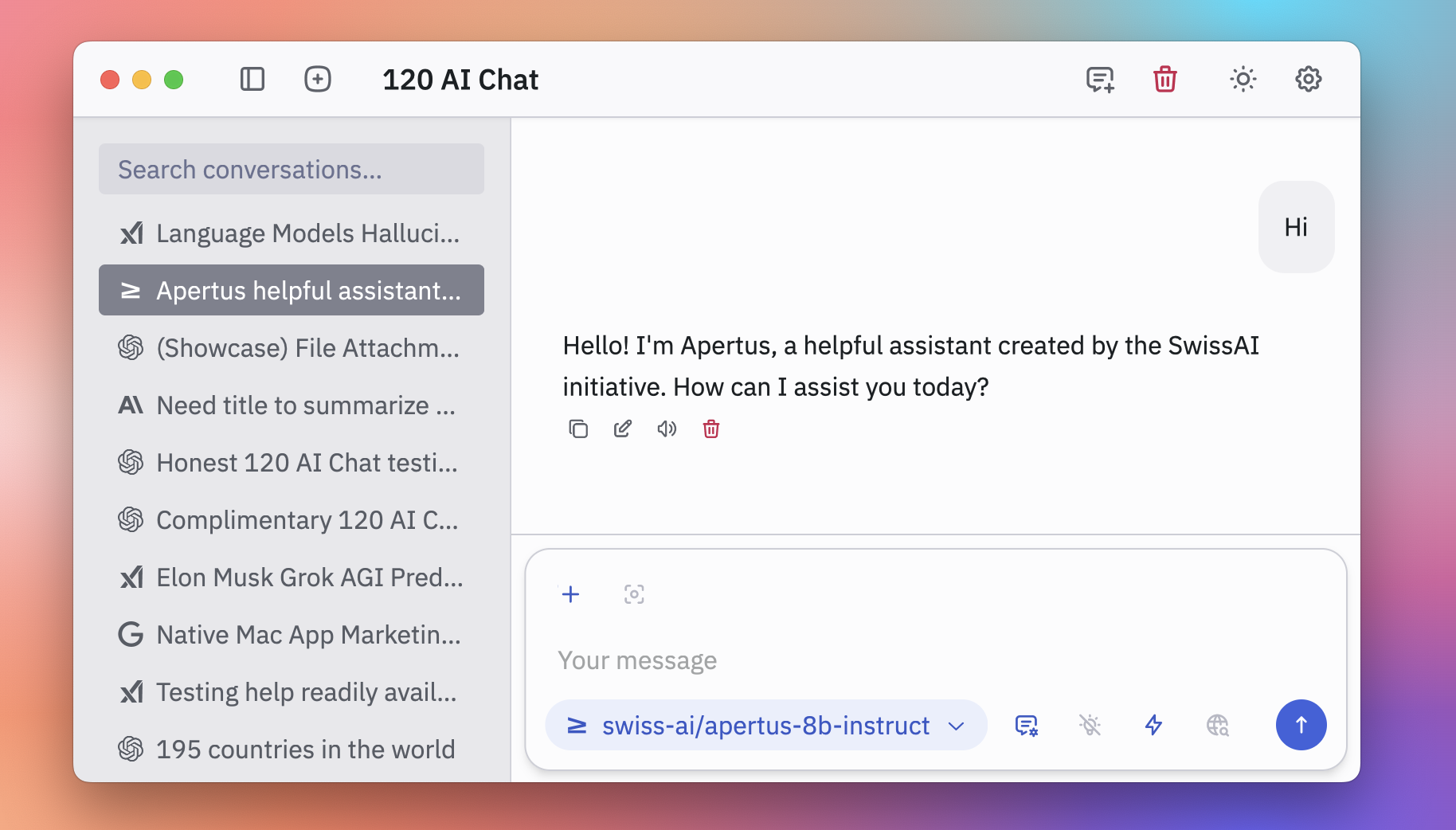
Support for Swiss AI models from the Apertus team is added, providing free access to these models in 120 AI Chat.
Access details: No API costs required; configure through the app's model settings. These models focus on neutral, helpful responses for tasks like research or explanations.
Use in chats: Switch to Swiss AI in multi-model threads to compare outputs with other providers like Grok or Claude.
Compatibility: Fits with the app's threading system for consistent behavior across models.
Text-to-Speech with OpenAI Whisper
Text-to-speech is implemented using OpenAI Whisper, adding audio playback to messages in conversations.
Playback options: A speaker icon on each message converts text to audio. Supports system audio settings and routing, like to headphones.
Voice features: Produces clear audio for different content types, from technical notes to general text. Users can listen while multitasking.
Accessibility support: Helps with hands-free use or for those preferring audio over reading. Applies to both AI responses and user messages.
Looking forward
Next week we will be working on screenshot and screen capture tools, allowing direct capture of screen content into conversations for analysis. This will extend visual inputs to include on-screen elements like windows or areas.
We are also working on the Windows version, adapting features like file attachments and text-to-speech to that platform. The goal is to match the macOS experience with Windows-specific integrations and launch to Windows users in the next couple of weeks.